

ビッグデータの活用が注目される中、誰でも閲覧可能なWebサイト上のオープンデータの活用に注目が集まっています。Webサイト上にあるオープンデータは競合調査やリスト作成、分析用など様々な分野で活用することができます。
しかし、これらを手動で収集しようと思うと、非常に時間がかかるうえその精度も危ぶまれます。そんな時にWebスクレイピング(クローリング)の技術が必要となるでしょう。WebスクレイピングはWebサイト上にある様々なデータを自動で収集する技術のことをいいます。
本記事では、Webスクレイピングの起源からスクレイピングがこれまでどのように活用され、今後どのような課題と展望があるのかをご紹介します。
目次
Webスクレイピング(クローリング)の歴史と推移
Webスクレイピングのアイデア自体はWWW(World Wide Web)が開発された時点、すなわち1989年から存在し、実際の技術であるWebクローリングが開発されたのは1993年と言われています。当初はWebのサイズを測るために開発されましたが、そこからWebの検索エンジンへの利用へと昇華されました。その後2004年にPython言語で開発されたHTML解析フレームワークのBeautifulSoupが開発され、Webスクレイピングの実装がより容易になり、注目を一気に浴びるようになりました。
Google Trendsにおける2004年1月からのWeb Scrapingの興味指数の推移をみてみましょう。BeautifulSoupが開発された2004年当時は一時的に高い値を示していましたが、以降しばらくは低い値で横這いとなっており、その後2010年代半ばごろから再び上昇を続けています。2020年以降は少し下降傾向にあるものの、興味指数は50以上を示しており、その重要性が認識されていることがわかります。(図1)

図1. Web Scraping興味指数推移 by Google Trends
この背景には2010年代から始まっている、業界全体のトレンドとなっている”データ活用”の影響が見て取れます。ここでのデータ活用には、BIツール等によるデータ分析とAIやRPAによる意思決定自動化、プロセス自動化の2大ビッグトレンドを含んでいますが、Data Analytics(データ分析)のトレンド推移をみてもその形状がWebスクレイピングとほぼ同じであることが分かります。(図2)スクレイピングはその特徴から自動Webデータ収集、Webデータのビジネス利用、データドリブンによる意思決定に最大限に活用でき、ここからもWebスクレイピングの興味が増していることが分かります。
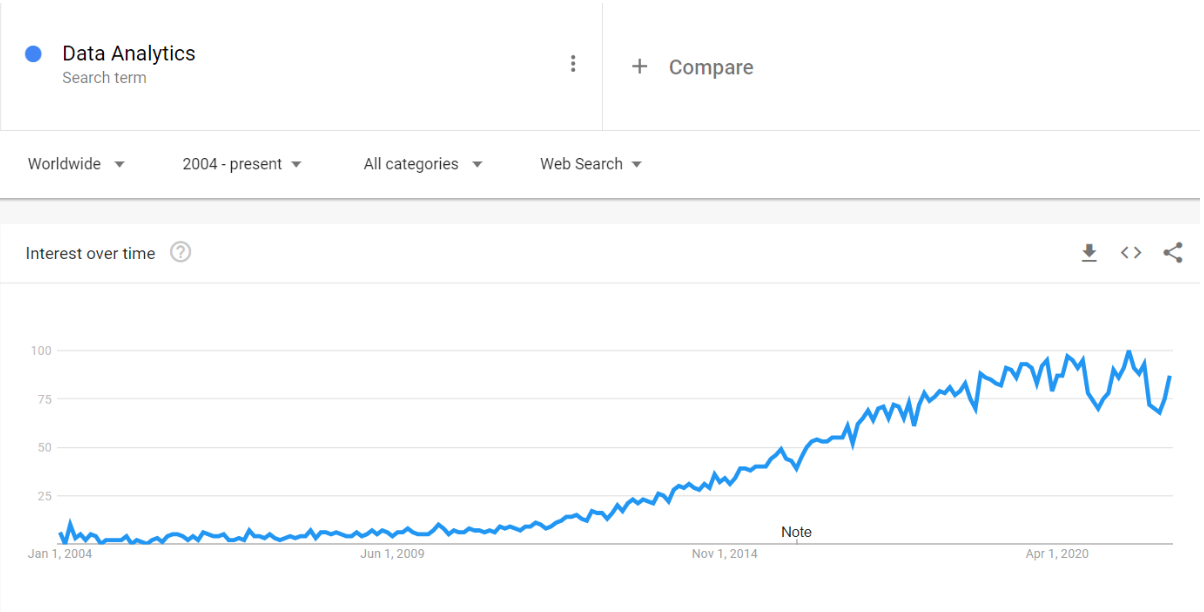
図2. Data Analytics興味指数推移 by Google Trends
また、Xbyte.ioは2012年からWebクローリングサービスを提供しており、1か月毎のWebクローリング回数を公開していますが、それによると2012年から2019年で約33倍以上回数が増加したといっています。

上記の通り、Webスクレイピングの需要が世界的に増していることが分かりました。次に、Webスクレイピングのサービスがどのように変化してきているかをみてみましょう。
Webスクレイピング(クローリング)サービスの傾向
サービスの利用用途
以下のグラフはWebスクレイピングの利用用途別の割合を示したものです。グラフにある通り、Webスクレイピングの利用用途は大きく4つに分類されます。

参考:The Economics Of Web Scraping Report
1.Content Scraping(38%)
製品情報や特定テキストの抽出
2.Research(25.9%)
新製品等の情報をいち早く察知し市場調査に活用
3.Contact Scraping(19.1%)
企業や個人のコンタクト情報を収集
4.Price Comparison(16.1%)
競合他社との比較のため他社製品の価格情報を取得
上記のグラフは2018年のものですが、現在(2022年)においても利用用途カテゴリは大きく変わっていません。
Webスクレイピングを利用する業界
次に業界別の利用割合を見てみましょう。
以下の円グラフの通り、Ecommerce(EC)業界での利用が全体の約半分の割合を占めています。次いでリクルートメント、旅行業界、不動産業界という順で利用割合が高くなっています。

小売りEC業界におけるスクレイピングの利用は古くから行われており、競争が激しく消費者の利用頻度が最も高いEC業界で他社に勝つには市場データをリアルタイムに取得し、価格やプロモーションに適切に反映させる必要があるため、Webスクレイピングは必要不可欠なツールとなっています。
次いでリクルートにおいて、適切な候補者をLinkedInなどのSNSから見つけ出す目的と、求人情報をIndeedなど1か所に収集する目的があり、Webスクレイピングが有効なツールとして広く活用されています。
上図のデータは2018年のものですが、加えて現在は金融業界においてのWebスクレイピングの利用が注目を浴びています。特に投資領域で利用されており、例えばベンチャーキャピタルは新たな投資先の発掘のためWebスクレイピングサービスを利用しており、2018年には1日当たり10億ほどのページがスクレイプされていましたが、2022年にはそのページ数が25億に増加すると言われています。
他にも、株式情報のリサーチや株価に影響を及ぼすであろう世界情勢や全国ニュースの収集と分析、金融業界における規制変更の察知などに利用されています。投資家にとってリアルタイムの情報と分析は非常に重要であり、Webスクレイピングのさらなる活用が期待されています。
Webスクレイピング(クローリング)の課題
Webスクレイピング(クローリング)を行うにはいくつかの課題があります。どのような課題があるのかひとつずつ説明します。
法的な問題
Webスクレイピングの最大の懸念として法律的な問題が指摘されています。基本的にはWebスクレイピング自体は違法な技術ではありません。Webスクレイピングはあくまでパブリックに公開されているデータを収集する技術であり、それ自体がハッキングツールとして認識されていません。
一方で、収集したデータが著作権で守られている場合は、その取扱いに注意が必要となります。例えば、FacebookはPower Ventures Inc.がユーザ情報をWebスクレイピングしている過程でFacebookのWebサイトをコピーしたとされ、このプロセスが直接的および間接的な著作権侵害の両方を引き起こすと主張して裁判で認められました。
またGDPRなどのプライバシー保護法も注意が必要となります。結論として、Webスクレイピングそのものは違法ではないが、著作権、利用規約、そしてプライバシー保護法などを十分に気を付けてから取り組む必要があり、スクレイピングサービス企業はクライアントが安心して利用できるようにこれらの点についてきちんと対応をとることが求められます。
Robots.txt
Robots.txtはWebサイトの運営側がどのURLや要素をスクレイプしてよいか、禁止か、頻度はどれぐらいかなどのルールを定めたファイルであり、スクレイパーは内容にそって対応をする必要があります。なお、共通の法的な決まりがあるわけではなく、あくまでWebサイト側の決めごとのため、Webサイト側に直接交渉をすることは問題ありません。
Websiteからのブロック
基本的にWebサイト側はサーバーへの負荷やWebアクセス解析にノイズがでることからWebスクレイピングを好ましく思わず、サイバーセキュリティ対策も含めていくつかの対策を行っていることがあります。代表的なものにIPブロックやCaptchaブロックがあります。IPブロックは、頻繁にアクセスのあるIPアドレスをブロックするもの、Captchaブロックはアクセスがロボットか人間かどうかを判別するためのテストをします。この対策にはプロキシの利用やCaptchaソルバーの導入が考えられます。
動的コンテンツ
動的コンテンツとは、ユーザの特徴、属性に応じてWebサイトのコンテンツを動的に変更する仕組みのことです。例えば、Netflixのレコメンデーションも動的コンテンツといえます。
これはBotが静的なhtml要素をスクレイピングする場合に課題となりますが、高度なプログラムを組み込むことで動的コンテンツでもスクレイピングが可能となります。
Webサイト構造の変化、複雑化
基本的にWebスクレイピングはhtmlやJava Scriptの要素をベースにデータ抽出を行うため、Webサイトの構造が変わるとBotも都度再プログラミングする必要があります。頻繁に構造が変化するサイトや、ページごとの構造が一定ではない複雑なWebサイトではスクレイピングが難しくなります。
Honeypots
Honeypotsとは、WebサイトにわざとハッカーやBotがアクセスしたくなるようなコンテンツを仕掛けておき、Botがそこにアクセスした場合は無限ループへ落とし込み、プログラムがエラーを起こすようにする仕組みのことです。また、その無限ループにおちいったIPをブロックするなどの対応もとられてしまい、そのWebサイトをスクレイピングすることがより難しくなります。
このように、Webスクレイピングが実現できても、ルールや規制に反している場合はそのデータを利用できず、最悪裁判沙汰になる可能性もあります。そのため、Webスクレイピングを実装する場合は、利用者並びにサービス提供側が倫理的な利用、透明性、セルフ規制の3つに必ず注意する必要があり、これらはスクレイピング業界で最も重視するべきことです。
倫理的な利用では、取得するデータの種類や利用規則にきちんと則っているかを確認すること、もし懸念がある場合は、透明性という観点からユーザサイドに全ての懸念点を晒しだすことが大切です。
そしてセルフ規制では、現在世界共通の規制はないものの、自分で規制ポリシーを作り、そのポリシーに反していないかをセルフチェックするプロセスを組み込むことです。
基本的にこれらは技術的に実現するものではなく、如何に最新のコンプライアンスポリシーにアンテナをはり、スクレイピングがいかなるルールにも反していないかをマニュアルでモニタリングする仕組みを実装することになります。そのため、サービス提供側に法務部門があるか、上記についてどのような姿勢で取り組んでいるかをユーザ側は気にする必要があります。

Webスクレイピング(クローリング)の最新トレンド
次に、Webスクレイピングサービスのトレンドについて説明します。
技術面のトレンド
Webスクレイピングそのものの技術はすでに確立されており、beautifulSoupなどhtml解析フレームワークが広く利用されています。そもそもスクレイピングサービス企業は解析技術そのものの強化は狙っていません。スクレイピングの目的はWebから必要なデータを正しく収集することであり、その目的を妨害する様々な課題に対して如何に対策をとり、クライアントが安心して利用できる環境を提供しているかが重要なポイントとなっています。リトアニアにあるWebスクレイピングサービス企業のOxylabsは、現在の業界トレンドはEthics(倫理感、法的な対応など)、データの質、そしてMLやAIの利用である、と同社主催のカンファレンスOXYCONで述べています。(参考)
収集技術の強化とは別に、Webスクレイピングの技術面において、Botが安定稼働するために如何にWebサイトからブロックされないような仕組みを組み込むかが重要となっています。そこで現在のトレンドとして活用され始めているのがAI/MLです。例えば、AIによるブロック検知、AIによるCAPTCHAソルバー、AIによるスクレイピング最適化があげられます。AIによるブロック検知では、htmlを分析する際に、ブロック機構が組み込まれているかを予測します。CAPTCHAソルバーは以前より存在する技術でしたが、AIによりその精度が高まっています。そしてWebスクレイピング最適化とは、無駄なトラフィックを排除してWebサイト側への負荷を減らし無駄な疑いをなくしたり、AIによってアクセスパターンをまるで人間が行っているようにシミュレーションしたりする技術です。従来の手段に加え、AIを用いた最新の技術を用いることで、Webスクレイピングをさらに安定して運用することが可能となります。
サービス面のトレンド
サービス面にもトレンドがあります。サービス面では、Webスクレイピングサービス企業がスペシャリストとして積極的にクライアントの要件を聞き出し、最適な設計を行えるかが重要となります。
ここでの最適な設計とは、ユーザーがどのデータを必要としているかを正確に把握することからはじまります。これを考えるときは必ずデータクオリティも考慮に入れることが重要です。データクオリティの重要なポイントとして、雑音が入っていないか、スペルミスはないか、更新頻度などを含む10つのポイントをDataWorksの設立者であるAllen O’Neillがカンファレンスで述べています。
そして、次に考えるべきはどこでそのデータを取得するかであり、ここで法的な面も考慮していく必要があります。上記の設計は残念ながら技術ではカバーできない部分が多く、専門家によるコンサルティングが必要となります。今後Webスクレイピング市場が拡大していく中で、ユーザーが安心して利用してもらうために質の高いサービスを提供できるかどうかが一つの大きな差別化要因となるでしょう。
現在、ノーコーディングでのプログラム実装を強みとするスクレイピングサービス企業は複数みられます。しかしながら、ユーザー自身で法的な課題を解消することは困難であり、大規模なスクレピングになると必ず専門家が必要となります。またノーコーディングプログラミングは汎用RPAツールに占領されることが想定されるため、大きな差別化要因とはならないと考えられます。
また、ユーザーは柔軟な料金体系を求めています。例えば、Botが必要でないときは課金しない、得られるデータ量で課金する、など動的な料金体系にすることが求められています。
今後の対策
先に挙げた課題に対する対策について以下の表にまとめました。ユーザーがWebスクレイピングサービスに求めるものは、そのサービスがユーザーの機能要件を満たすものであることはもちろん、Botが安定稼働しかつ高い抽出成功率をほこり、かつ法的な懸念に対応しているかどうかが合わせて非常に重要となっています。そのため、ユーザーはきちんと対策が取られているかを見極める必要があり、サービス提供側はいかに対策に取り組んでいるかの透明性が求められます。
| 課題 | 具体的な対策 |
|---|---|
| 法的な問題 | 最新のコンプライアンスポリシー(GDPR、CCPAなど)に関して把握する。 |
| Robots.txt | スクレイピング実装前にRobots.txtを確認するプロセスを入れ、実現可否を判断する。 |
| Websiteからのブロック |
プロキシサーバを利用し、異なるIPアドレスを利用する。 |
| 動的コンテンツ | Bot側のプログラム設計で対応する。特定の場所の要素を取るようにするのでなく、html全体をスキャンし必要なデータを抽出する。 |
| Webサイト構造の変化、複雑化 |
ターゲットWebサイトのhtml構造変更を自動で検知する仕組みの実装。 |
| Honeypots |
Bot側のプログラムで対応(Hidden要素を排除するなど) |
まとめ
本記事ではスクレイピング(クローリング)の歴史からトレンドや課題、課題に対する対策などをご紹介しました。スクレイピングは長く活用されてきた技術であり、データ活用がすすむ現代においてより多くの注目を浴びています。今はECや求人など特定の業界での活用が主であるからこそ、他業界でスクレイピングを活用することで、競合企業より先手にでるチャンスがあるともいえるでしょう。しかし活用には問題点もいくつかあります。スクレイピングサービス提供者が問題点に対してどのような対策をしているのかを提示するのはもちろん、ユーザー側もしっかり確認して安心できるサービス提供者を選ぶ必要があります。
日本ではまだスクレイピングを専門としている企業は多くありません。そんななかで弊社が提供するPigDataはスクレイピングを専門として多くのお客様の課題を解決してきました。PigDataは法律的観点、技術的観点でもスクレイピングに対する知識や倫理観を持ってお客様のご要望にお応えしていきます。スクレイピングをお考えの際はぜひお問い合わせください。


